
海洋生態学実習 2: アマモ場の生物群集
Garis besar topik
-
-
【多様性の解析】
仮に種数が同じ群集であっても、各種の個体数の相対的な比率(均等性)の違いによって、その群集の豊富さは異なった印象を与えるであろう。多様度指数とは、「種の豊富さ」と「種組成の均等さ」の2つの要素により群集の多様性を表す指標で、種数と各種の個体数から計算する。よく使われる指数として次の2つのものがある。
Shannon-Weiner 多様度指数

シンプソンの多様度指数

いずれも、S: は種数、pi: 全個体数の中でi種が占める割合(相対優占度) を示す。
-
数値例を示す。種数が同じでも均等性の違いにより多様度指数が異なるのがわかる。

-
【群集の類似度の解析】
類似度指数は、2つの群集で出現する種構成と各種の個体数が全く同じ場合を100%、全く異なる(共通種が1種もでない)場合を0%として、その違いを連続的に表すものである。多数の異なる方法が開発されているが、今回は下式に示すBray-Curtis similarity indexを利用する。
Sjk: j番目のサンプルとk番目のサンプルの類似度
Yij: j番目のサンプルのi番目の種の個体数(現存量、被度)
類似度指数は2群集ごとのペア間で求める値なので、nサンプルからなるデータセットの場合はn(n-1)/2の類似度が求まることになる。これを対戦表の形で表したものを類似度行列を呼ぶ。
類似度行列を元に、群集間の類縁関係を視覚的に表す方法が多数開発されてきる。大きく分けると、1) 類似度の大きさに応じて群集を分類(分割)するclustering (クラスター解析)という方法と、群集の類似度の違いを距離の差に見立てて2次元(3次元)空間にプロットするordinationという方法の2種類がある。それぞれの方法の特徴、利点、欠点を理解するには多変量統計解析の知識が必要であるが、ここでは、比較的簡単なクラスター解析による群集の分類を行う。クラスター解析では、より似通った群集がより近い位置になるように群集の位置を配置する。その方法も多数あるが、今回は手計算でできるgroup-average linkageによる連結法を紹介する。 -
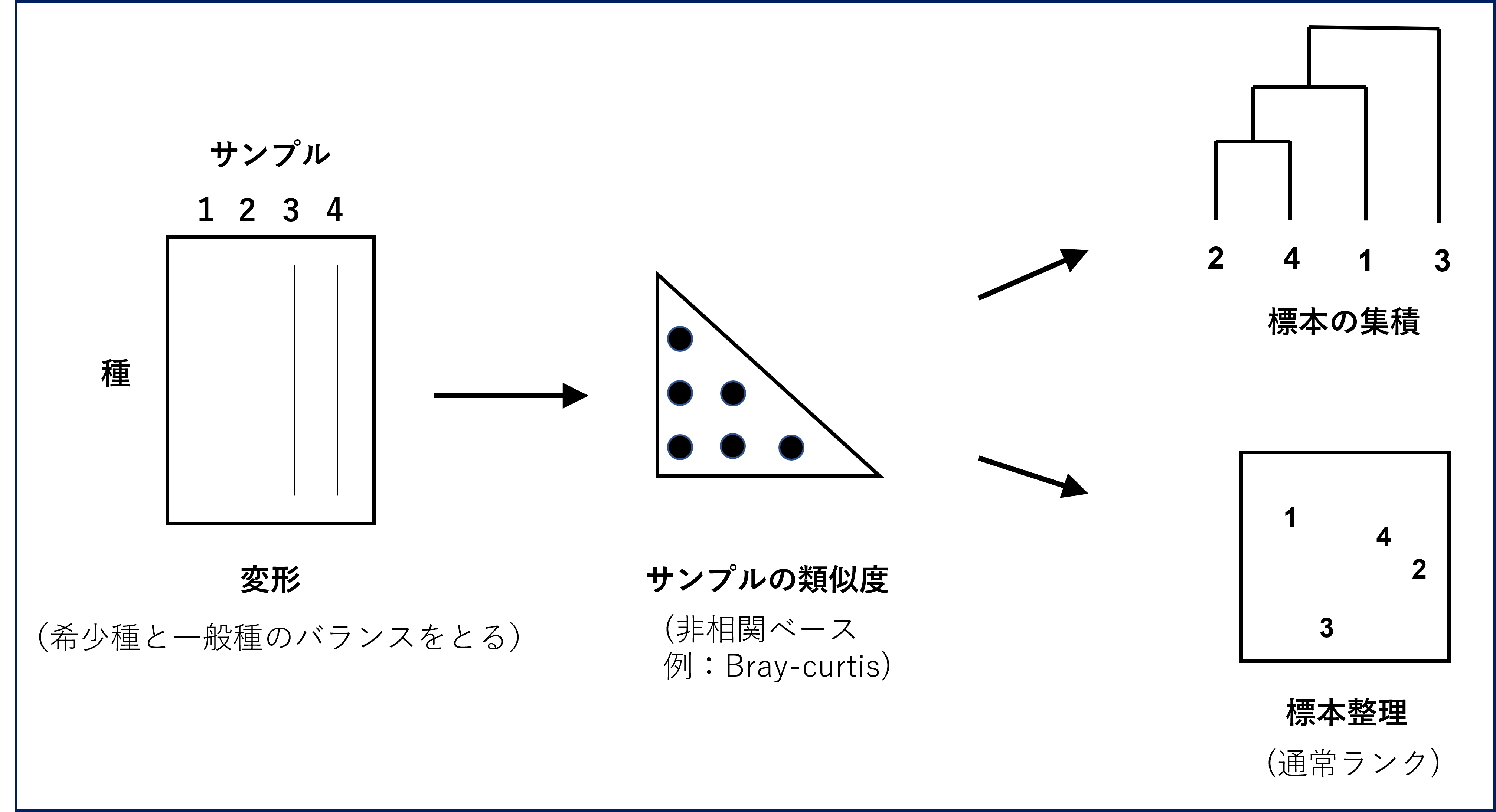
-
-
1:元の4x4の類似度行列ではsample 2と4の類似度[S(2,4)=68.1%]が最も高いので、この2つをまず連結
2:sample 2と4のデータを合わせた3x3の類似度行列を作成 S(1,2&4)=[S(1,2)+S(1,4)]/2=38.9%、S(3,2&4)=[S(3,2)+S(3,4)]/2=55.0%
3:3x3の群集行列ではS(3,2&4)が最大なので、次にこの2つを連結
4:最後に1と2&3&4を連結 S(1,2&3&4)=[S(1,2) + S(1,3)+ S(1,4)]/3=25.9%
群集構造のデータ表
類似度行列(連結前)

類似度行列(2&4を連結後)

類似度行列(2&3&4を連結後)


-
-


